To make artificial intelligence systems more powerful, tech companies need online data to feed the technology. Here’s what to know.
Online data has long been a valuable commodity. For years, Meta and Google have used data to target their online advertising. Netflix and Spotify have used it to recommend more movies and music. Political candidates have turned to data to learn which groups of voters to train their sights on.
Over the last 18 months, it has become increasingly clear that digital data is also crucial in the development of artificial intelligence. Here’s what to know.
The more data, the better.
The success of A.I. depends on data. That’s because A.I. models become more accurate and more humanlike with more data.
In the same way that a student learns by reading more books, essays and other information, large language models — the systems that are the basis of chatbots — also become more accurate and more powerful if they are fed more data.
Some large language models, such as OpenAI’s GPT-3, released in 2020, were trained on hundreds of billions of “tokens,” which are essentially words or pieces of words. More recent large language models were trained on more than three trillion tokens.
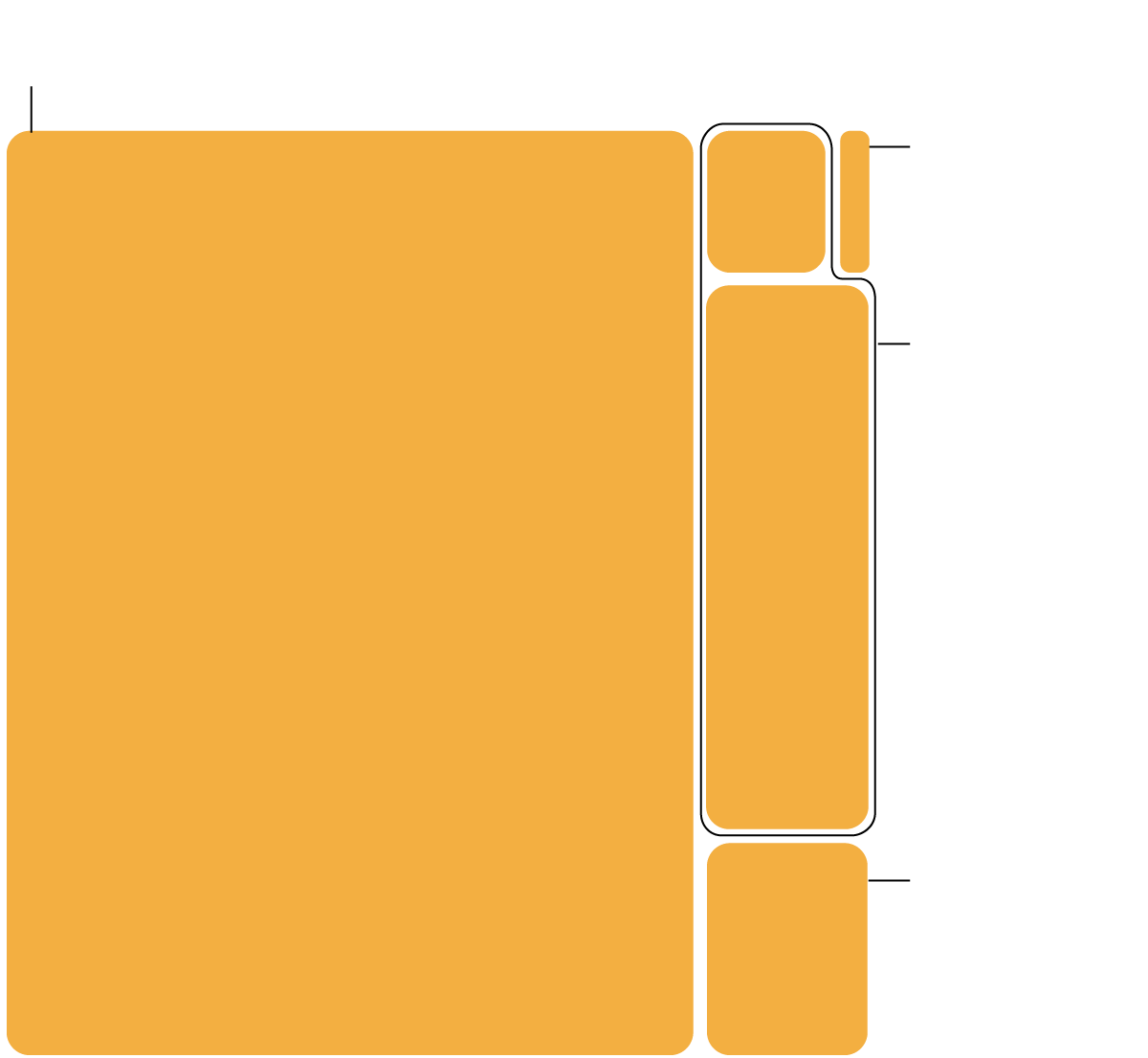
The Data Inside GPT-3
OpenAI’s groundbreaking A.I. model was trained on billions of websites, books and Wikipedia articles collected from across the internet. OpenAI did not share the data it used to train its recent models.
#g-gpt3-breakdown-box ,
#g-gpt3-breakdown-box .g-artboard {
margin:0 auto;
}
#g-gpt3-breakdown-box p {
margin:0;
}
#g-gpt3-breakdown-box .g-aiAbs {
position:absolute;
}
#g-gpt3-breakdown-box .g-aiImg {
position:absolute;
top:0;
display:block;
width:100% !important;
}
#g-gpt3-breakdown-box .g-aiSymbol {
position: absolute;
box-sizing: border-box;
}
#g-gpt3-breakdown-box .g-aiPointText p { white-space: nowrap; }
#g-gpt3-breakdown-Artboard_1 {
position:relative;
overflow:hidden;
}
#g-gpt3-breakdown-Artboard_1 p {
font-family:nyt-franklin,arial,helvetica,sans-serif;
font-weight:300;
line-height:19px;
opacity:1;
letter-spacing:0em;
font-size:16px;
text-align:left;
color:rgb(0,0,0);
text-transform:none;
padding-bottom:0;
padding-top:0;
mix-blend-mode:normal;
font-style:normal;
height:auto;
position:static;
}
#g-gpt3-breakdown-Artboard_1 .g-pstyle0 {
font-weight:700;
height:19px;
top:1.3px;
position:relative;
}
#g-gpt3-breakdown-Artboard_1 .g-pstyle1 {
height:19px;
top:1.3px;
position:relative;
}
#g-gpt3-breakdown-Artboard_1 .g-pstyle2 {
font-weight:700;
line-height:17px;
height:17px;
font-size:14px;
text-align:center;
color:rgb(255,255,255);
top:1.1px;
position:relative;
}
#g-gpt3-breakdown-Artboard_1 .g-pstyle3 {
font-weight:700;
}
#g-gpt3-breakdown-Artboard_2 {
position:relative;
overflow:hidden;
}
#g-gpt3-breakdown-Artboard_2 p {
font-family:nyt-franklin,arial,helvetica,sans-serif;
font-weight:300;
line-height:19px;
opacity:1;
letter-spacing:0em;
font-size:16px;
text-align:left;
color:rgb(0,0,0);
text-transform:none;
padding-bottom:0;
padding-top:0;
mix-blend-mode:normal;
font-style:normal;
height:auto;
position:static;
}
#g-gpt3-breakdown-Artboard_2 .g-pstyle0 {
font-weight:700;
line-height:13px;
height:13px;
font-size:11px;
text-align:center;
color:rgb(255,255,255);
top:0.9px;
position:relative;
}
#g-gpt3-breakdown-Artboard_2 .g-pstyle1 {
font-weight:700;
height:19px;
text-align:center;
color:rgb(255,255,255);
top:1.3px;
position:relative;
}
#g-gpt3-breakdown-Artboard_2 .g-pstyle2 {
font-weight:700;
line-height:11px;
height:11px;
font-size:10px;
text-align:center;
color:rgb(255,255,255);
top:0.8px;
position:relative;
}
#g-gpt3-breakdown-Artboard_2 .g-pstyle3 {
font-weight:700;
line-height:12px;
height:12px;
font-size:10px;
text-align:right;
top:0.8px;
position:relative;
}
#g-gpt3-breakdown-Artboard_2 .g-pstyle4 {
font-weight:700;
}
#g-gpt3-breakdown-Artboard_2 .g-cstyle0 {
font-weight:700;
}
Common Crawl
Text from web pages collected since 2007.
Wikipedia
(3 billion tokens)
English-language
Wikipedia pages.
12
billion
Books 1 and Books 2
OpenAI has not explained the contents of these datasets. They are believed to contain text from millions of published books.
55 billion
410 billion tokens
WebText2
Web pages linked from Reddit that received three or more upvotes – an indication of approval from users.
19 billion
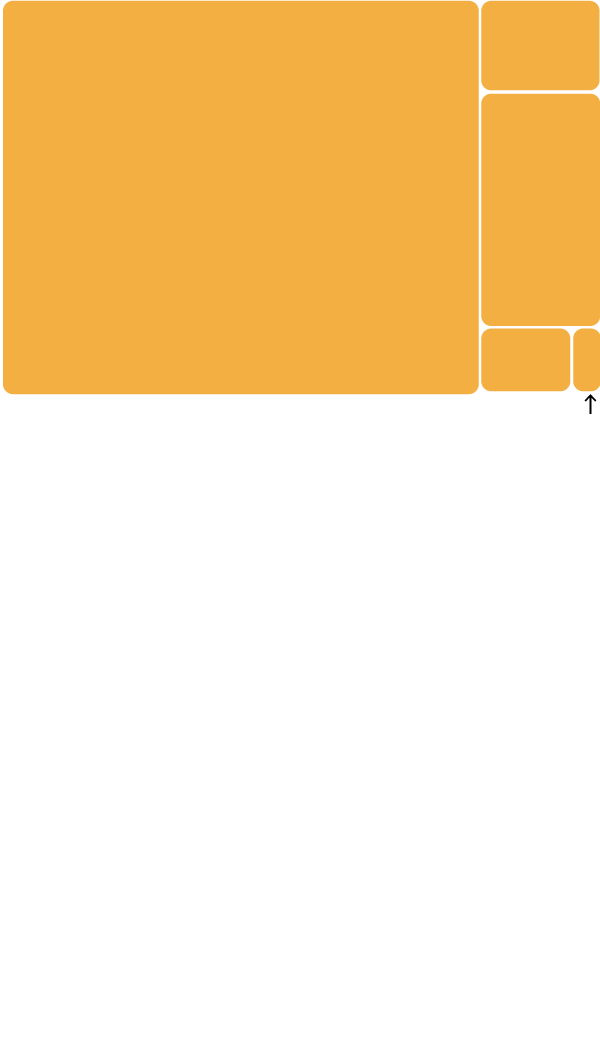
WebText2
19 billion
Common Crawl
410 billion tokens
Books 2
55 billion
Books 1
12 billion
Wikipedia
Common Crawl: Text from web pages collected since 2007.
WebText2
Web pages linked from Reddit that received three or more upvotes – an indication of approval from users.
Books 1 and Books 2: OpenAI has not explained the contents of these datasets. They are believed to contain text from millions of published books.
Wikipedia: English-language Wikipedia pages.